Monolith vs. Microservices
Microservices sind nicht automatisch besser – dieser Guide zeigt, wann der modulare Monolith die klügere Wahl ist und wie du dir die Migration offen hältst.
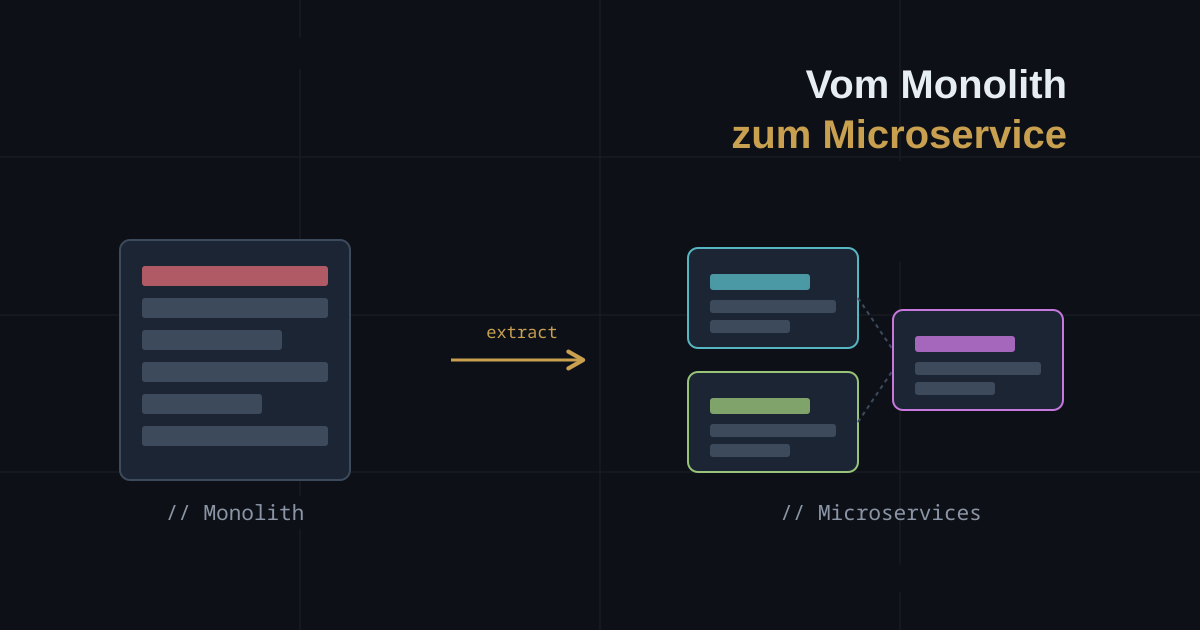
Monolith vs. Microservices: Wann was, und wie man sich nicht verbaut
Kaum eine Architekturentscheidung wird so emotional diskutiert wie die Frage „Monolith oder Microservices?”. Conference-Talks feiern Microservices als den einzig wahren Weg, Blogposts mit Titeln wie „Wir sind zurück zum Monolithen gewechselt” gehen viral. Die Wahrheit ist – wie so oft – langweiliger: Es kommt darauf an.
Dieser Artikel räumt mit ein paar Mythen auf, gibt konkrete Entscheidungshilfen und zeigt vor allem eines: wie du ein Projekt von Anfang an so aufsetzt, dass aus einem Monolithen später ohne Totalumbau Microservices werden können. Mit Codebeispielen in C#.
Worüber wir eigentlich reden
Bevor wir vergleichen, kurz die Begriffe scharf stellen – denn viele Diskussionen scheitern an unterschiedlichen Definitionen.
Ein Monolith ist eine Anwendung, die als eine Einheit deployt wird. Das bedeutet nicht automatisch „Spaghetti-Code” oder „eine riesige Klasse”. Ein gut strukturierter Monolith kann intern sauber in Module getrennt sein – man spricht dann von einem modularen Monolithen. Der entscheidende Punkt: ein Build-Artefakt, ein Deployment, ein Prozess.
Ein Microservice-System besteht aus mehreren unabhängig deploybaren Diensten, die jeweils einen fachlichen Bereich abdecken und über das Netzwerk (HTTP, gRPC, Messaging) kommunizieren. Jeder Service hat im Idealfall seine eigene Datenbank und sein eigenes Deployment-Lifecycle.
Wichtig: Der Gegensatz ist nicht „chaotisch” vs. „sauber”. Beide Architekturen können sauber oder chaotisch sein. Der Gegensatz ist ein Deployment-Artefakt vs. viele Deployment-Artefakte – mit allen Konsequenzen, die das für Komplexität, Betrieb und Organisation hat.
Die ehrliche Gegenüberstellung
Wofür der Monolith spricht
Einfachheit im Betrieb. Ein Prozess, ein Log-Stream, ein Deployment. Du brauchst kein Service-Mesh, kein verteiltes Tracing, keine Container-Orchestrierung, um produktiv zu sein. Für ein kleines Team ist das ein enormer Vorteil.
Einfaches Refactoring. Ändert sich eine Schnittstelle zwischen zwei Modulen, fängt der Compiler den Fehler ab. Bei Microservices merkst du es im besten Fall im Integrationstest, im schlimmsten Fall in Produktion.
Transaktionen sind trivial. Ein BEGIN TRANSACTION über mehrere Tabellen ist in einer Datenbank ein gelöstes Problem. Über Servicegrenzen hinweg brauchst du Sagas, Kompensationslogik oder eventuelle Konsistenz – ein ganzer Komplexitätsberg.
Schnelle lokale Entwicklung. F5 drücken und die ganze Anwendung läuft. Kein Hochfahren von acht Containern, kein Mocken fremder Services.
Wofür Microservices sprechen
Unabhängige Skalierung. Wenn dein Bildverarbeitungs-Endpunkt CPU-hungrig ist, der Rest aber nicht, skalierst du nur diesen einen Dienst – statt der ganzen Anwendung.
Unabhängiges Deployment. Team A deployt zehnmal am Tag, ohne auf den Release-Zyklus von Team B zu warten. Das ist der eigentliche organisatorische Gewinn.
Technologische Freiheit. Ein Dienst in C#, ein rechenintensiver Teil in Rust, ein ML-Dienst in Python – jeder Service wählt sein Werkzeug.
Fehlerisolation. Stürzt ein Microservice ab, kann der Rest (mit ordentlichen Fallbacks) weiterlaufen. Im Monolithen reißt ein Memory Leak die ganze Anwendung mit.
Was Microservices kosten
Diese Liste wird gern verschwiegen. Microservices tauschen Code-Komplexität gegen operative Komplexität – und letztere ist oft teurer:
- Verteilte Systeme sind schwer. Netzwerklatenz, Teilausfälle, Retries, Idempotenz, das CAP-Theorem – all das wird plötzlich dein tägliches Problem.
- Debugging über Servicegrenzen erfordert verteiltes Tracing (OpenTelemetry o. Ä.). Ohne das tappst du im Dunkeln.
- Daten-Konsistenz wird zur Architekturaufgabe statt zur Datenbankfunktion.
- Infrastruktur-Overhead: CI/CD-Pipelines pro Service, Service Discovery, API-Gateways, zentrales Logging.
- Lokale Entwicklung wird langsamer und komplizierter.
Faustregel: Wähle Microservices wegen organisatorischer oder skalierungsbedingter Zwänge – nicht, weil die Architektur „modern” aussieht.
Eine Entscheidungshilfe
Statt einer Pro/Contra-Liste hier konkrete Fragen. Je mehr du mit „ja” beantwortest, desto eher sprechen die Argumente für Microservices.
- Hast du mehrere Teams, die sich beim Deployment gegenseitig blockieren?
- Hast du nachgewiesene, ungleichmäßige Skalierungsanforderungen (nicht „könnte mal sein”, sondern Lastdaten)?
- Ist deine Organisation reif für DevOps – also gibt es Leute, die Kubernetes, Observability und CI/CD pro Service stemmen können?
- Sind deine fachlichen Domänen klar abgegrenzt und stabil?
- Ist die Codebasis schon so groß, dass Builds und Tests unzumutbar langsam sind?
Wenn du gerade ein neues Projekt mit einem kleinen Team startest, lautet die Antwort fast immer: Beginne mit einem Monolithen. Aber – und das ist der Kern dieses Artikels – mit einem modularen Monolithen, der die spätere Aufteilung nicht verbaut.
Diese Strategie nennt sich „Monolith First” und wurde unter anderem von Martin Fowler popularisiert: Man lernt die Domäne erst kennen, bevor man Servicegrenzen in Stein meißelt. Eine falsch gezogene Servicegrenze ist deutlich teurer zu korrigieren als eine falsch gezogene Modulgrenze.
Der modulare Monolith: Aufbau für die spätere Migration
Die zentrale Idee: Strukturiere deinen Monolithen so, als wären die Module bereits Services – nur ohne den Netzwerk-Layer dazwischen. Wenn die Disziplin stimmt, ist das Herauslösen eines Moduls später eine mechanische, keine archäologische Arbeit.
Vier Prinzipien tragen das:
1. Schneide nach fachlichen Domänen, nicht nach technischen Schichten
Ein klassischer Fehler ist die Projektstruktur Controllers/, Services/, Repositories/. Das gruppiert Code nach Technik. Wenn du später „die Bestellungen” herauslösen willst, ist Bestell-Code über alle drei Ordner verstreut.
Schneide stattdessen nach Domäne. Eine sinnvolle Solution-Struktur für einen E-Commerce-Monolithen:
MyShop.sln
├── src/
│ ├── MyShop.Host/ // ASP.NET Core Host, fügt alle Module zusammen
│ ├── Modules/
│ │ ├── Orders/
│ │ │ ├── MyShop.Orders.Api/ // öffentliche Schnittstelle des Moduls
│ │ │ ├── MyShop.Orders.Domain/ // Entities, Domänenlogik
│ │ │ └── MyShop.Orders.Infrastructure/ // DB-Zugriff, externe Adapter
│ │ ├── Catalog/
│ │ │ ├── MyShop.Catalog.Api/
│ │ │ ├── MyShop.Catalog.Domain/
│ │ │ └── MyShop.Catalog.Infrastructure/
│ │ └── Payments/
│ │ └── ...
│ └── Shared/
│ └── MyShop.SharedKernel/ // Contracts, Basis-Typen, EventsJedes Modul ist eine in sich geschlossene Einheit. Wenn aus Orders ein Microservice wird, ziehst du den ganzen Orders/-Ordner um und gibst ihm einen eigenen Host – die fachliche Logik bleibt unangetastet.
2. Module kommunizieren nur über explizite Contracts
Module dürfen sich gegenseitig nicht in die internen Klassen greifen. Erlaubt ist ausschließlich der Aufruf über eine veröffentlichte Schnittstelle. In C# erzwingst du das über die Projekt-Referenzen: Das Catalog-Modul darf nur MyShop.Orders.Api referenzieren, niemals MyShop.Orders.Domain oder .Infrastructure.
Das Api-Projekt enthält nur Interfaces und DTOs – keine Implementierung:
// MyShop.Orders.Api/IOrderService.cs
namespace MyShop.Orders.Api;
public interface IOrderService
{
Task<OrderDto> PlaceOrderAsync(PlaceOrderRequest request, CancellationToken ct);
Task<OrderDto?> GetOrderAsync(Guid orderId, CancellationToken ct);
}
// Bewusst flache DTOs – kein Durchreichen von Domänen-Entities!
public sealed record PlaceOrderRequest(Guid CustomerId, IReadOnlyList<OrderLine> Lines);
public sealed record OrderLine(Guid ProductId, int Quantity);
public sealed record OrderDto(Guid Id, Guid CustomerId, decimal Total, string Status);Die Implementierung liegt versteckt im Infrastructure- oder Domain-Projekt und wird per Dependency Injection registriert:
// MyShop.Orders.Infrastructure/OrderService.cs
internal sealed class OrderService : IOrderService // internal! Nicht von außen sichtbar.
{
private readonly OrdersDbContext _db;
public OrderService(OrdersDbContext db) => _db = db;
public async Task<OrderDto> PlaceOrderAsync(PlaceOrderRequest request, CancellationToken ct)
{
var order = Order.Create(request.CustomerId, request.Lines);
_db.Orders.Add(order);
await _db.SaveChangesAsync(ct);
return order.ToDto();
}
public async Task<OrderDto?> GetOrderAsync(Guid orderId, CancellationToken ct)
{
var order = await _db.Orders.FindAsync([orderId], ct);
return order?.ToDto();
}
}Jedes Modul bringt seine eigene DI-Registrierung mit – eine einzige öffentliche Methode pro Modul, mehr „Oberfläche” gibt es nicht:
// MyShop.Orders.Infrastructure/OrdersModule.cs
public static class OrdersModule
{
public static IServiceCollection AddOrdersModule(
this IServiceCollection services, IConfiguration config)
{
services.AddDbContext<OrdersDbContext>(opt =>
opt.UseNpgsql(config.GetConnectionString("OrdersDb")));
services.AddScoped<IOrderService, OrderService>();
return services;
}
}Der Host fügt nur noch zusammen:
// MyShop.Host/Program.cs
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddOrdersModule(builder.Configuration);
builder.Services.AddCatalogModule(builder.Configuration);
builder.Services.AddPaymentsModule(builder.Configuration);
var app = builder.Build();
app.MapControllers();
app.Run();3. Trenne die Daten schon im Monolithen
Das ist der Punkt, an dem die meisten Migrationen später scheitern. Wenn alle Module in denselben Tabellen wühlen und du munter über Modulgrenzen hinweg joinst, ist die Datenbank ein einziger verklebter Block – egal wie sauber dein Code ist.
Die Lösung im Monolithen: ein eigenes Datenbankschema pro Modul, und striktes Verbot von modulübergreifenden Joins.
// MyShop.Orders.Infrastructure/OrdersDbContext.cs
public sealed class OrdersDbContext : DbContext
{
public DbSet<Order> Orders => Set<Order>();
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// Eigenes Schema -> klare Eigentumsgrenze
modelBuilder.HasDefaultSchema("orders");
modelBuilder.ApplyConfigurationsFromAssembly(typeof(OrdersDbContext).Assembly);
}
}Orders darf also nicht einfach SELECT ... FROM catalog.products machen. Braucht das Bestellmodul Produktdaten, fragt es über das ICatalogService-Interface an – genau wie es das später über einen HTTP-Call tun würde. Die Tabellen können physisch in derselben Datenbank liegen; entscheidend ist, dass logisch keine Modul ins Schema eines anderen greift.
Bei der Migration ziehst du das Schema in eine eigene Datenbank um – und der Code merkt davon nichts, weil er sowieso nie cross-schema gejoint hat.
4. Nutze Events für lose Kopplung
Direkte synchrone Aufrufe zwischen Modulen sind in Ordnung, wenn ein Modul sofort eine Antwort braucht. Für „nebenbei”-Reaktionen – „eine Bestellung wurde aufgegeben, also reduziere den Lagerbestand und schicke eine Mail” – sind Events besser. Sie entkoppeln Sender und Empfänger vollständig.
Im Monolithen kannst du Events erstmal über einen einfachen In-Memory-Bus laufen lassen (z. B. MediatR oder eine eigene kleine Abstraktion):
// MyShop.SharedKernel/IEventBus.cs
public interface IEventBus
{
Task PublishAsync<TEvent>(TEvent @event, CancellationToken ct) where TEvent : class;
}
// MyShop.SharedKernel/Events/OrderPlacedEvent.cs
public sealed record OrderPlacedEvent(
Guid OrderId, Guid CustomerId, decimal Total, DateTime OccurredAt);Das Orders-Modul publiziert, ohne zu wissen, wer zuhört:
public async Task<OrderDto> PlaceOrderAsync(PlaceOrderRequest request, CancellationToken ct)
{
var order = Order.Create(request.CustomerId, request.Lines);
_db.Orders.Add(order);
await _db.SaveChangesAsync(ct);
await _eventBus.PublishAsync(
new OrderPlacedEvent(order.Id, order.CustomerId, order.Total, DateTime.UtcNow), ct);
return order.ToDto();
}Das Payments-Modul reagiert in seinem eigenen Code, ohne dass Orders davon weiß:
// MyShop.Payments.Infrastructure/OrderPlacedHandler.cs
internal sealed class OrderPlacedHandler : IEventHandler<OrderPlacedEvent>
{
public Task HandleAsync(OrderPlacedEvent e, CancellationToken ct)
{
// Zahlung anstoßen ...
return Task.CompletedTask;
}
}Der entscheidende Vorteil: Tauschst du den In-Memory-Bus später gegen einen echten Message Broker (RabbitMQ, Azure Service Bus, Kafka) aus, ändert sich am Publishing- und Handler-Code nichts. Nur die IEventBus-Implementierung wird ausgewechselt. Eine Warnung dazu: Ein In-Memory-Bus läuft in derselben Transaktion und im selben Prozess; ein echter Broker tut das nicht. Für wirklich zuverlässige Zustellung brauchst du dann das Outbox-Pattern – das solltest du im Hinterkopf behalten, aber im Monolithen noch nicht verfrüht einbauen.
Der Migrationsschritt: ein Modul herauslösen
Angenommen, das Orders-Modul wird zum Engpass und soll ein eigener Service werden. Dank der Vorarbeit ist das überschaubar:
Schritt 1 – Eigener Host. Du legst ein neues Projekt MyShop.Orders.Service an, das die bestehenden Orders.Domain- und Orders.Infrastructure-Projekte referenziert und HTTP-Endpunkte bereitstellt:
// MyShop.Orders.Service/Program.cs
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddOrdersModule(builder.Configuration); // exakt dieselbe Methode wie vorher!
var app = builder.Build();
app.MapPost("/orders", async (PlaceOrderRequest req, IOrderService svc, CancellationToken ct)
=> Results.Ok(await svc.PlaceOrderAsync(req, ct)));
app.MapGet("/orders/{id:guid}", async (Guid id, IOrderService svc, CancellationToken ct)
=> await svc.GetOrderAsync(id, ct) is { } o ? Results.Ok(o) : Results.NotFound());
app.Run();Die AddOrdersModule-Methode und die gesamte Domänenlogik bleiben unverändert. Das ist der Lohn der Disziplin.
Schritt 2 – Aufrufer umstellen. Im Monolithen referenzierten andere Module IOrderService direkt. Jetzt brauchen sie eine HTTP-basierte Implementierung desselben Interfaces. Weil alle Aufrufer ohnehin nur das Interface kannten, ist das ein lokaler Austausch:
// Im verbleibenden Monolithen: HTTP-Adapter statt In-Process-Aufruf
internal sealed class HttpOrderServiceClient : IOrderService
{
private readonly HttpClient _http;
public HttpOrderServiceClient(HttpClient http) => _http = http;
public async Task<OrderDto> PlaceOrderAsync(PlaceOrderRequest request, CancellationToken ct)
{
var resp = await _http.PostAsJsonAsync("/orders", request, ct);
resp.EnsureSuccessStatusCode();
return (await resp.Content.ReadFromJsonAsync<OrderDto>(ct))!;
}
public async Task<OrderDto?> GetOrderAsync(Guid orderId, CancellationToken ct)
=> await _http.GetFromJsonAsync<OrderDto?>($"/orders/{orderId}", ct);
}Registrierung im verbleibenden Monolithen:
builder.Services.AddHttpClient<IOrderService, HttpOrderServiceClient>(client =>
client.BaseAddress = new Uri(builder.Configuration["Services:Orders"]!));Wichtig: Spätestens hier musst du Netzwerkfehler einplanen. Ein In-Process-Aufruf schlägt nie wegen Timeouts fehl, ein HTTP-Aufruf schon. Resilienz-Bibliotheken wie Polly (bzw. Microsoft.Extensions.Http.Resilience) geben dir Retries, Timeouts und Circuit Breaker.
Schritt 3 – Daten trennen. Das orders-Schema zieht in eine eigene Datenbank. Weil nie cross-schema gejoint wurde, ist das ein reiner Infrastruktur-Schritt ohne Code-Änderung. Brauchte der Service vorher per Event eine Reaktion eines anderen Moduls, ersetzt du den In-Memory-Bus durch den echten Broker.
Schritt 4 – Schrittweise statt Big Bang. Migriere jeweils nur ein Modul. Nach jedem Schritt hast du ein lauffähiges System – ein hybrides aus „Restmonolith plus einige Services”. Das ist völlig in Ordnung und meist sogar das stabile Zielbild. Niemand zwingt dich, am Ende jedes Modul herauszulösen. Module, die selten geändert werden und nicht skalieren müssen, dürfen für immer im Monolithen bleiben.
Häufige Fehler
Verfrühte Aufteilung. Microservices zu bauen, bevor man die Domäne versteht, führt zu falsch geschnittenen Servicegrenzen – dem teuersten Fehler überhaupt. Eine Modulgrenze verschiebt der Compiler mit, eine Servicegrenze erfordert einen koordinierten Multi-Repo-Umbau.
Der verteilte Monolith. Das schlechteste Ergebnis: Services, die so eng gekoppelt sind, dass sie nur gemeinsam deploybar sind – du hast die operative Komplexität von Microservices und die Starrheit eines Monolithen. Entsteht meist durch geteilte Datenbanken oder zu chatty Schnittstellen.
Geteilte Datenbank zwischen Services. Wenn zwei Services dieselben Tabellen schreiben, kann keiner sein Schema unabhängig ändern. Die Datenbank ist dann die heimliche Kopplung, die alle Vorteile zunichtemacht.
Eine gemeinsame „Shared”-Bibliothek für alles. Ein kleiner Shared Kernel mit stabilen Contracts ist gut. Eine wachsende Common.dll, in der die halbe Geschäftslogik liegt, koppelt wieder alle aneinander.
Microservices ohne Observability. Ohne zentrales Logging und verteiltes Tracing ist ein Microservice-System in Produktion praktisch nicht zu debuggen. Diese Werkzeuge sind kein Nice-to-have, sondern Voraussetzung.
Fazit
Die Wahl ist kein Glaubensbekenntnis. Für die meisten neuen Projekte – besonders mit kleinem Team – ist der modulare Monolith die richtige Startentscheidung: Er liefert schnell, ist einfach zu betreiben und zu refactoren, und lässt dich die Domäne kennenlernen, bevor du teure Grenzen ziehst.
Der Trick ist, ihn von Anfang an so zu bauen, dass die Tür zu Microservices offen bleibt: Schnitt nach Domänen statt nach Schichten, Kommunikation nur über explizite Contracts, getrennte Datenbankschemata und Events für lose Kopplung. Mit dieser Disziplin wird die spätere Migration zu einer Reihe überschaubarer, mechanischer Schritte statt zu einem riskanten Totalumbau.
Und vielleicht stellst du irgendwann fest, dass dein modularer Monolith einfach gut genug ist. Auch das ist ein völlig legitimes Ergebnis.